1.下载安装包
2.选择地址
我的地址选为/usr/local/hadoop
mkdir /usr/local/hadoop
3.配置环境变量
vim /etc/profile
#添加如下
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH修改以后执行配置
source /etc/profile
4.HDFS配置安装
1.编辑core-site.xml文件
vim /usr/local/hadoop/etc/hadoop/core-site.xml
#在configuration中配置如下
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
<description>表示HDFS的基本路径</description>
</property>
2.创建 NameNode 和 DataNode 需要的文件目录
创建 NameNode 需要存储数据的文件目录
mkdir -p /home/dfs/name
## 创建 DataNode 需要存放数据的文件目录
mkdir -p /home/dfs/data
3.修改 hdfs-site.xml 配置文件
vim /usr/local/hadoop/etc/hadoop/hdfs-site.vml
#在configuration中配置如下
<property>
<name>dfs.replication</name>
<value>1</value>
<description>表示数据块的备份数量,不能大于DataNode的数量</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop-twq/bigdata/dfs/name</value>
<description>表示 NameNode 需要存储数据的文件目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop-twq/bigdata/dfs/data</value>
<description>表示 DataNode 需要存放数据的文件目录</description>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>192.168.0.10:50090</value>
##如果secondarynamenode为多个话可以设置为0.0.0.0:50090
</property>
<property>
<name>dfs.http.address</name>
<value>192.168.0.10:50070</value>
</property>
4.修改 slaves 文件
vim /usr/local/hadoop/etc/hadoop/slaves
#删除localhost,添加节点名称,如:
node01
node02
5.配置 Hadoop 依赖的 JAVA_HOME
vi hadoop-env.sh
#添加如下配置
export JAVA_HOME=/usr/local/java
6.拷贝配置到node01和node02
将 NameNode 存储的文件目录以及 DataNode 存储的文件目录拷贝到 node01和node02 中
scp -r /home/dfs root@node01:/home
scp -r /home/dfs root@node02:/home
## 将在 master 中配置好的 hadoop 安装目录拷贝到 slave1 和 slave2 中
scp -r /usr/local/hadoop root@node01:/usr/local
scp -r /usr/local/hadoop root@node02:/usr/local
7.启动验证
格式化 HDFS 集群的 namenode
hdfs namenode -format
#运行hdfs
/usr/local/hadoop/sbin/start-dfs.sh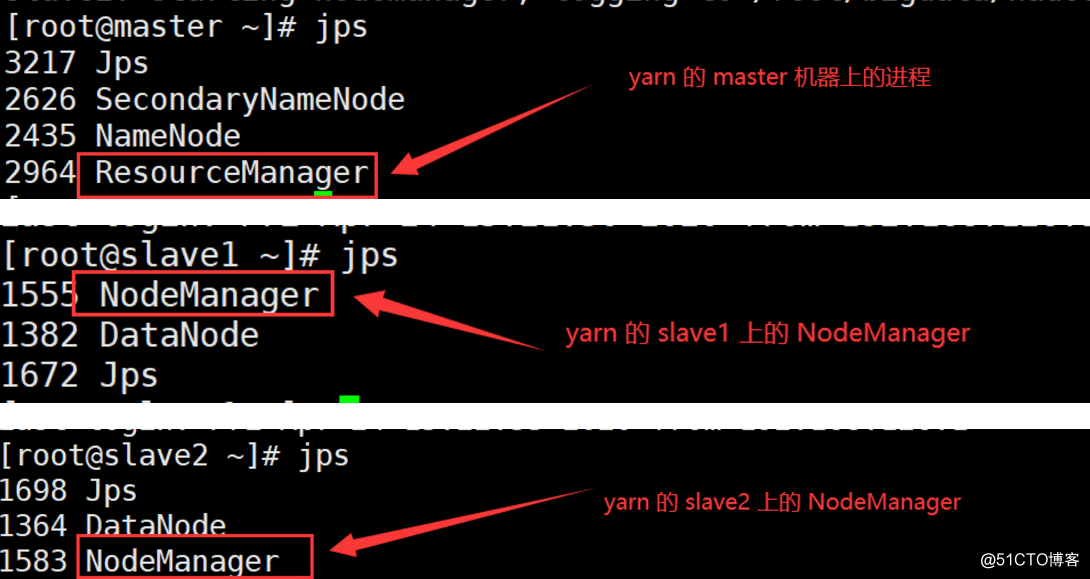{kind=link}
8.停止 HDFS 集群
#停止hdfs
/usr/local/hadoop/sbin/stop-dfs.sh
5.yarn配置安装
1.创建 Yarn 存储临时数据的文件目录
mkdir -p /home/yarn/local-dir
2.修改 yarn-site.xml 配置文件
vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
#在configuration中添加如下
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<description>表示ResourceManager安装的主机</description>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
<description>表示ResourceManager监听的端口</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/yarn/local-dir</value>
<description>表示nodeManager中间数据存放的地方</description>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1630</value>
<description>表示这个NodeManager管理的内存大小</description>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
<description>表示这个NodeManager管理的cpu个数</description>
</property>
3.拷贝 yarn 相关配置到 node01 和 node02 中
scp /usr/local/hadoop/etc/hadoop/yarn-site.xml root@node01:/usr/local/hadoop/etc/hadoop/
scp /usr/local/hadoop/etc/hadoop/yarn-site.xml root@node02:/usr/local/hadoop/etc/hadoop/
scp -r /home/yarn/local-dir root@node01:/home
scp -r /home/yarn/local-dir root@node02:/home
4.启动验证
#启动yarn
/usr/local/hadoop/sbin/start-yarn.sh
5.停止yarn
#停止yarn
/usr/local/hadoop/sbin/stop-yarn.sh
6.MapReduce 配置安装
1.修改 yarn-site.xml 配置
vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
#在configuration下添加如下
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>为map reduce应用打开shuffle 服务</description>
</property>
2.修改mapred-site.xml配置
<property>
<name>mapred.job.tracker</name>
<value>192.168.0.10:9001</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3.将 MapReduce 相关的配置文件同步到 node01 和 node02 上
scp yarn-site.xml mapred-site.xml root@node01:/usr/local/hadoop/etc/hadoop
scp yarn-site.xml mapred-site.xml root@node02:/usr/local/hadoop/etc/hadoop[clickshow]这一步跟上一步yarn一起做就行[/clickshow]
4.验证 MapReduce
准备目录和数据
hadoop fs -mkdir /input
hadoop fs -put /usr/local/hadoop/etc/hadoop /input
hadoop fs -rm -r /output
## 执行 MapReduce 任务
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar grep /input/hadoop /output 'dfs[a-z.]+'出现以下画面

说明mapreduce配置也是正确的
7.遇到的问题
1.非本机无法访问50070端口
我遇到这个问题是因为防火墙没有关闭,我只关闭了firewalld,没有关闭iptables
查看防护墙状态
service iptables status
关闭
service iptables stop
查看防火墙开机启动状态
chkconfig iptables --list
关闭开机启动
chkconfig iptables off
2.将hadoop的启动方式加入systemctl中
可以复制下面的模板自己更改
#Unit表明该服务的描述,类型描述。
[Unit]
Description=hadoop #描述服务名
After=network.target #服务级别,低于network,也可以理解为network启动后再启动Hadoop
#关键部分,用于设置一些关键参数
[Service]
Type=forking #以fork方式从父进程创建子进程
User=root
Group=root
ExecStart=/usr/local/hadoop/sbin/start-all.sh #启动目录
ExecStop=/usr/local/hadoop/sbin/stop-all.sh
PrivateTmp=true #是否给服务分配独立的临时空间
#Install定义如何启动,以及是否开机启动
[Install]
WantedBy=multi-user.target #当前 Unit 激活时(enable)符号链接目录3.Container [pid=28920,containerID=container_1389136889967_0001_01_000121] is running beyond virtual memory limits. Current usage: 1.2 GB of 1 GB physical memory used; 2.2 GB of 2.1 GB virtual memory used. Killing container.
在mapred-site.xml中添加如下代码:
<property>
<name>mapreduce.map.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>8192</value>
</property>